In order to drive safely, autonomous vehicles on public roads need to know where they are in the world. Tasks easy for humans, such as staying in driving lanes at all times, would be impossible for an autonomous vehicle to perform without highly accurate vehicle location information. Determining the vehicle’s location in the world is called localization. One popular and well-known localization system is the global positioning system (GPS), which can provide rough localization; it often has accuracy of one to three meters, but the accuracy can decrease to upwards of fifty meters with poor line off sight to the sky or other interference. Unfortunately, this is not accurate enough for an autonomous vehicle; a localization accuracy of under ten centimeters is considered the upper limit for safe driving.
Like the techniques involved in object tracking using extended and unscented Kalman filters, localization techniques are often probabilistic. The unscented Kalman filter is flexible enough for many object tracking applications; however, when even higher accuracy is required for vehicle localization, another technique can be used: a particle filter.
Exploring my implementation
All of the code and resources used in this project are available in my Github repository. Enjoy!
Technologies Used
- C++
- uWebSocketIO
Particle Filters
Particle filters are similar to unscented Kalman filters in that they update the state of an object (for example, the location and orientation) by transforming a set of points through a function to predict a future state, given noisy and partial observations of the world. However, unlike unscented Kalman filters, particle filters may choose points to transform at random, rather than from a Gaussian distribution. This eliminates the need to assume a static state motion or measurement model. The number of points required for a particle filter to obtain the same level of accuracy as an unscented Kalman filter is generally higher, which makes a particle filter more computationally complex and memory intensive. Additionally, there is a choice to be made regarding the number of particles included in the filter (the time complexity of computing the algorithm is linear in the number of particles). However, particle filters do converge to the true state of the object being predicted as number of particles increases, unlike unscented Kalman filters, which have no such convergence properties.
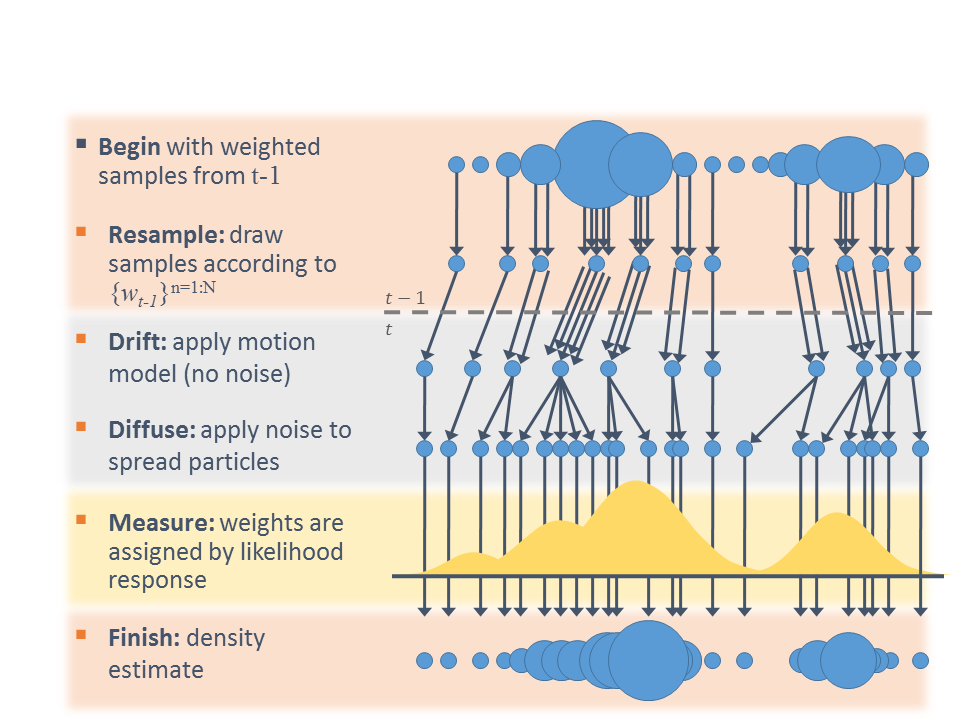
In a particle filter, the points, or “particles”, are chosen to represent concrete guesses as to the actual state being predicted. At each time step, particles are randomly sampled from the state space. The probability of a particle being chosen is proportional to the probablility of it being the correct state, given the sensor measurements seen so far. The update step in a particle filter can be seen as selecting the most likely hypotheses among the set of guessed states; as more sensor measurements become available, those more likely to be true are kept, while those less likely are removed.
Particle filters for localization
When used for localization, particle filters become a particularly effective technique. Because they can approximate non-parametric functions, they perform better in many non-linear model environments, including situations with multiple possible localization positions. For example, when using a Kalman filter (extended or unscented), a vehicle driving down a road with many similar lampposts may decide that it is next to a lamppost, but may have trouble determining which lamppost it is next to.
In using a particle filter for localization, data from onboard sensors (such as radar and lidar) can be used to measure distances to static objects (trees, poles, walls), which may involve sensor fusion. With a pre-loaded map which has trusted coordinates of these fixed objects, a particle filter matches observations of objects in the world against those in the map, and then determines where the vehicle is in the map space. To start, particles may initially be chosen at random from all locations, with no assumptions about where the vehicle is. However, in practice, some sort of one-time hint about the general location from GPS may be provided. At each time step, the algorithm uses its previous belief about vehicle location, the current vehicle control values, and sensor measurements, and outputs a new belief about the vehicle location.
The algorithm runs by updating the current set of particles (possible locations) according to the vehicle control command, simulating motion of all of the particles. For instance, if the vehicle is travelling forward, all particles move forward. If the vehicle turns to the right, all of the particles turn to the right. Because the result of a control does not always complete as expected, some amount of noise is added to the particle movement to simulate this uncertainty. Each particle is then considered to be the possible location of the vehicle, and the probability that the location is the true location of the vehicle given the current sensor measurements is computed. Those probabilities are used as weights to randomly select new particles from the previous particle list. Because of this, particles which are consistent with sensor measurements are more likely to be chosen (and may even be chosen more than once!), and particles which are inconsisent with the measurements are less likely to be chosen. However, to prevent convergence on an incorrect location (if the vehicle is stationary, for instance), extra uniformly sampled particles can be added.
With every iteration of the particle filter algorithm, the selected particles converge to the true location of the vehicle, which makes intuitive sense: as the vehicle senses more of its environment, it should be expected to become increasingly sure of its position.

Implementation
The localization algorithm exists as a loop, where new sensor measurements and control commands are read. On the first sensor measurement, the particle filter is initialized with that measurement; on subsequent measurements, the particle filter is run to predict the new location of the vehicle. Next, the particles have their weights updated using observations from sensors and known map landmarks, then particles are resampled. Finally, the particle with the highest weight is chosen as the new location of the vehicle.
Inside the particle filter, the initialization step creates 100 particles, locates them all at the first measurement, and then adjusts each particle randomly according to the sensor measurement uncertainty distribution. During prediction, each particle’s next location is predicted by moving it according to the velocity and turn rate from most recent vehicle control command.
To update the weights for each particle based on the sensor observations of landmarks, the landmarks nearest the particle are chosen. Next, each observation is paired with its closest true landmark. Finally, the particle’s weight is set to the product of the distance between each true landmark and its closest observation.
Particle resampling occurs according to the particles weights, which is a standard sampling with replacement approach.
Performance
To test the localization using the particle filter, the simulator provides sensor measurements of fixed objects in the world. These are plotted in the simulator as black crosses with circles around them. Green lines drawn between the vehicle and the circles indicate fixed objects which are being tracked.
The jitter between the vehicle (true location) and the grey circle (predicted location) is kept to a relative minimum over time, even during accelerations, decelerations, and turns. This indicates that the filter does a relatively good job at localization.