Exploring my implementation
All of the code and resources used in this project are available in my Github repository. Enjoy!
Stay tuned for a detailed post!
All of the code and resources used in this project are available in my Github repository. Enjoy!
Stay tuned for a detailed post!
For those of you who are eager to jump to the chase and use my PageAccel plugin, please head over to the PageAccel home page and install (should take 10 seconds, tops).
I recently learned about the Accelerated Mobile Pages (AMP) Project, an open-source initiative led by Google to accelerate content on mobile devices. The idea, in short, is this: by streamlining web page content to include only the most critical pieces, web users on mobile devices can experience pages which load faster, are easier to read, and do not have the “clunkiness” which plagues content originally created for desktop browsers. Google’s goal is two-fold: to drastically improve the mobile user experience by providing simplified web pages, as well as providing a programming framework for web designers and developers to use in creating this content.
According to a report at SearchEngineLand reported by Google, “The median load time for AMP is 0.7 seconds, the time it takes for your eye to blink twice. By contrast, the median load time for non-AMPs is 22.0 seconds, the time it takes for you to leave the site and never come back.” Which page would you rather view?
I recently started noticing some of this AMP content myself on my own mobile device, as Google has been incorporating AMP pages in its web search content for a several months now. From Google’s own blog post on the search result incorporation, “[this] shows an experience where web results that that have AMP versions are labeled with ![]() . When you tap on these results, you will be directed to the corresponding AMP page within the AMP viewer.”
. When you tap on these results, you will be directed to the corresponding AMP page within the AMP viewer.”
See Google’s own view of the differences side by side (on the left is a non-AMP experience, and the right is the AMP experience):
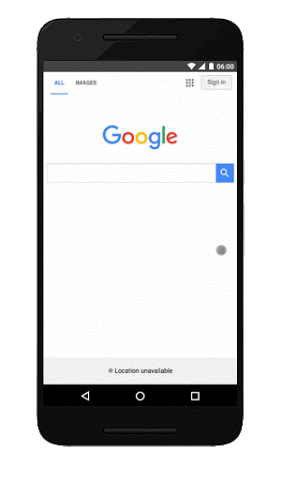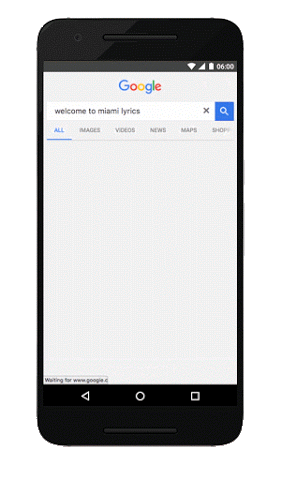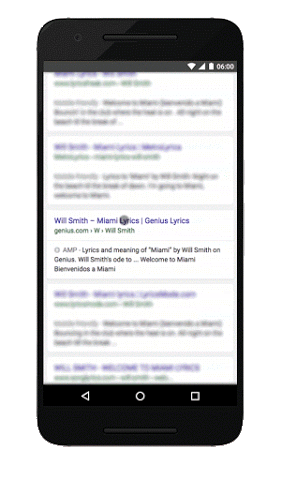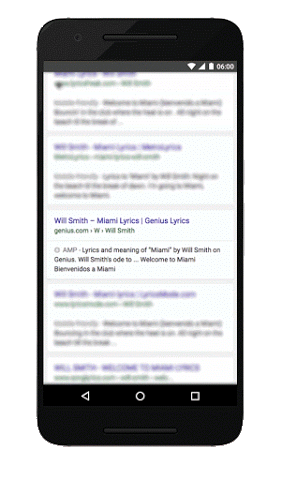
Here is an additional slide deck from Google, which describes the project:
If you’ve not viewed any AMP pages yourself, I’ll tell you that my own personal experience has been excellent. Having streamlined, faster loading pages without much of the cruft that typically is served has been excellent.
I quickly began craving this experience in my own desktop browser.
I started formulating some goals:
The more I pondered this, the more I realized that a simple Chrome extension (as Chrome is my current browser of choice) could likely achieve this. I had never built a Chrome extension before, and so this would be both a good learning experience and also provide an avenue to share my work with others (through the Chrome Web Store).
I set out to build my first Chrome extension. I won’t go into detail about the challenges that I faced in developing the work; I will say that I did learn quite a bit about the race conditions which quickly pop up when programming a Chrome extension (given Chrome’s highly asynchronous, callback-based APIs) and dealing with Chrome’s Web Store support team (which is highly automated and thin on actual humans to answer seemingly simple questions).
In the end, I had built my first simple Chrome extension, PageAccel, which is satisfying the goals that I laid out. It’s basic yet totally functional, doesn’t require any input from the user, and successfully detects when AMP content is available and switches the user to use that content seamlessly and painlessly. The extension indicates visually to the user when browsing AMP content, if it’s not already obvious due to the “lightining” fast load time and simplified pages (I chose a lightning icon for the extension itself). The entire project is open-sourced in GitHub, and I’m hoping to receive some feedback from the internet at large if others find this extension useful as I do!
Rather than explain with more words, I’ve included the screenshots which are part of the PageAccel page in the Chrome Web store:
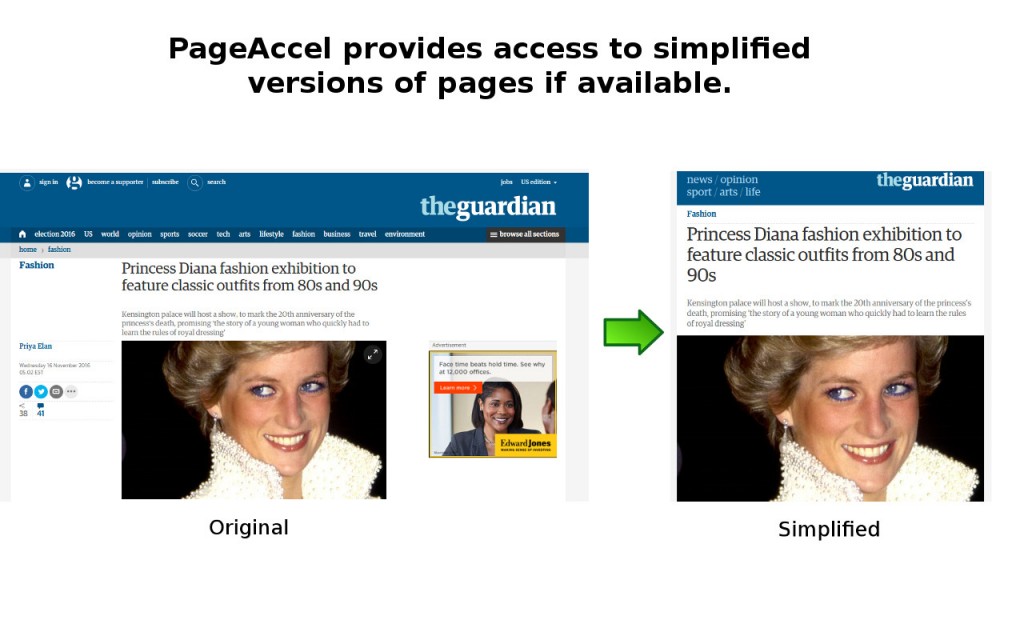
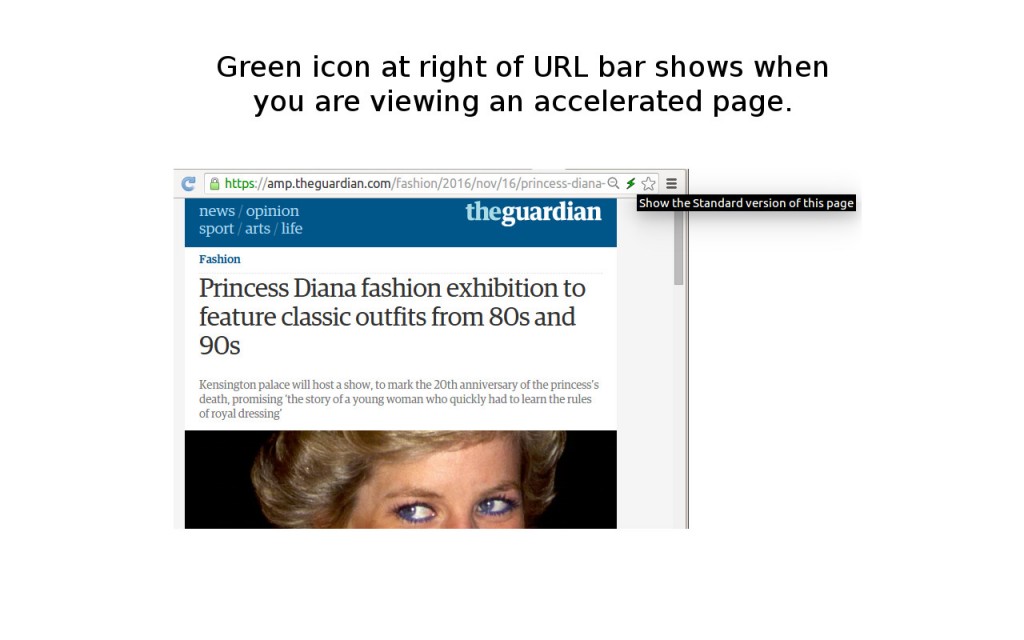
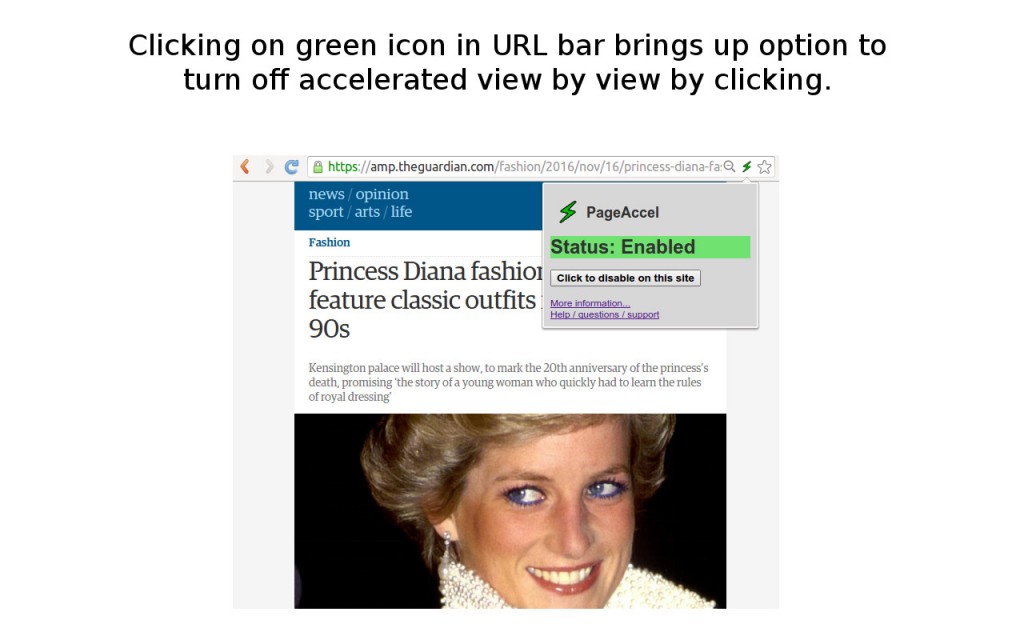
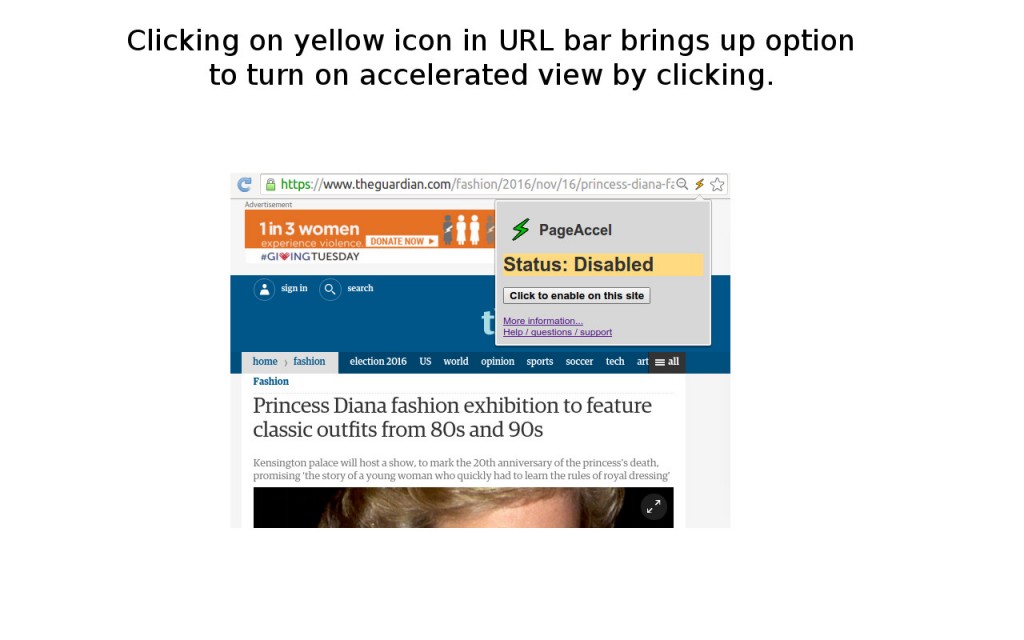
In my own use in the last few weeks (which of course is not a uniform sample of all web content), I’m seeing that somewhere between 10% – 25% of the pages that I visit have AMP content. Much of this simplified, accelerated content has been authored by mass media (some randomly selected news websites: BBC, The Guardian, CNN, and the like (c’mon NPR, switch over!)) and tech blogs and information sources (not a big surprise here). I’m hoping over time I’ll continue to see an uptick in fraction of pages which have AMP versions overall; if the growth rate reported by SearchEngineLand is any indication (“only three percent were using AMP in March 2016, versus 11.6 percent in June 2016”), then my extension will become more and more useful over time – at the very least, to me.

One of my earliest programming mentors introduced me to the concept of dependency injection and inversion of control, commonly shortened to DI/IOC, in my first year of my first real job as a professional programmer. This individual was known in the group for “pushing the envelope” of technologies and processes that we used to write software. They were also known for championing Ruby (right around the time of the original release of Ruby on Rails), promoting test driven development, and taking hours off to go shopping for shoes during the workday at a rather large global financial juggernaut (see my resume on LinkedIn if you’re curious about who this employer might have been). Dependency injection, at the time, was described to me as something which would “bring my code out of the dark ages” by eliminating reams of poorly written (and often “wrong”) singleton management and lifecycle management code. (I use the term “wrong” in the sense that Java Concurrency in Practice uses when it talks about how, for example, using the double-checked locking idiom for lazy initialization in Java without the volatile keyword is “wrong”.) As a wide eyed newbie programmer listening to a relative “god”, I was enamored with the power of DI and became a life-long convert.

There are literally hundreds, likely thousands, of articles, StackOverflow questions, blog posts, forum threads and other resources which speak about the merits of dependency injection and some of the frameworks which implement it. My goal with this post is not to provide a comprehensive treatment of why one should use DI, but rather to provide samples from my own personal experience to add to the conversation.
That being said, some online resources that seem good include:
In joining a new group at my current job, I stepped into a role as a software engineering lead and have recently found myself explaining the merits (and pitfalls!) of DI frameworks to un-initiates / skeptics. I should note that those who view DI frameworks with skepticism are not bad programmers by any means; on the contrary, they often write high quality, concise code. If anything, I myself suffer from the curse of knowledge regarding DI frameworks – Spring in particular. But much like my experience (and many other’s experiences) with technologies and methodologies that vary in “power”, technologies and methodologies “less powerful than [x] are obviously less powerful, because they’re missing some feature [they are] used to.” (I’m quoting from Paul Graham’s post on the power of languages, but I think the same argument works here for software design frameworks.) Again, I’ll quote (with some pronoun adjustments): “when our hypothetical [x] programmer looks in the other direction, up the power continuum, they don’t realize they are looking up. What they see are merely weird [technologies]. They probably consider them about equivalent in power to [x], but with all this other hairy stuff thrown in as well. [x] is good enough for them, because they think in [x].” In short, DI frameworks often looks as powerful as managing your own object graph and lifecycle but filled with lots of “hairy stuff thrown in as well” which seems superfluous – why should one go the trouble?
Regarding Spring as a DI framework – my opinion is that Spring is one of the best DI frameworks for the Java-based ecosystem. If you’re raising your eyebrows, I’m not surprised – over the many years that I’ve used DI frameworks, I’ve often gotten strange looks because I promote the use of Spring’s DI container. Most of the conversations that I have with Spring skeptics revolve around some basic mis-understandings of the framework itself. Let me try to set the record straight.
OK, I hope that’s all out of the way. Now, I’ll take a brief moment to highlight some of Spring’s benefits:
I am fully aware that there are numerous other DI frameworks on the market, both for Java and for Scala. I think some of them (notably Guice and Subcut) have very good points about them. However, I feel that they are not as robust as Spring’s DI offering, and this is why I am not highlighting their usage. I will leave a separate discussion of Spring vs other DI frameworks for another times.
I’ll continue this discussion based on sample code (https://github.com/dinoboy197/sailing-cruise-watcher) that I wrote using Scala and Spring together. The code was originally written to monitor a 2000s-era website for reservations availability for sailing classes, but that’s a different story entirely.
It is easy to DI-enable a class so that Spring will create an instance of it for injection into other classes and for lifecycle management. Simply add the javax.inject.Named annotation to the class:
import javax.inject.Named
@Named
class SampleProcessor {
Now, Spring will create and manage a single instance of the SampleProcessor class in your program; it can be injected anywhere.
To inject an instance of a class that you’ve annotated with @Named into a different class, use the @Inject annotation:
import javax.inject.Inject
import javax.inject.Named
// mark a class with @Named to create an instance of it in the object graph
@Named
// use @Inject() followed by constructor arguments to have Spring wire in instances of these classes
class SailingCruiseChecker @Inject() (val http: Http, val sampleProcessor: SampleProcessor) {
See that for the class SailingCruiseChecker, two other class instances are being injected: an instance of a SampleProcessor class and an instance of an Http class.
Some class instances are stateful; they may even require special handling during startup or shutdown. A startup example: a class may need to pre-load data from a dependent class before it can service its public methods; however, its dependent classes must be wired up before this happens. A shutdown example: a class may need to wait before exiting to properly close a thread pool, close JDBC connections, or save in-flight computations for proper continuation upon restart.
To specify a method which is called once automatically after the object graph is created, annotate it with javax.annotation.PostConstruct. To specify a method which is called once automatically before the object graph is torn down (either due to JVM shutdown or DI container closing), annotate it with javax.annotation.PreDestroy.
// if your singleton has some state which must be initialized only *after* the object graph is constructed
// (ie, it calls other objects in the object graph which might not yet be fully constructed)
// use this method
@PostConstruct
def start() {
// some initialization that is guaranteed to only happen once
}
@PreDestroy
def stop() {
// if your singleton has some state which must be shut down to cleanly stop your app
// (ex: database connections, background threads)
// use this method
}
Using libraries is common, and it’s easy to instantiate third party classes which are not DI-enabled within any code that you write. Take, for example, a class in a third party library called NonDIEnabledClass which has an initialization method called init() and a method to be called for cleanup before JVM shutdown called close():
// this is a fictitious example of such an external class which must be started with init() and stopped with close()
class NonDIEnabledClass {
def init {}
def doSomething{}
def close {}
}
Using this class in code might look like the following:
@Named
class Http {
private val httpHelper = new NonDIEnabledClass()
@PostConstruct
def start() {
httpHelper.start()
}
def get(url: String): String = {}
@PreDestroy
def init() {
httpHelper.stop()
}
}
The Http class is tightly coupled to the NonDIEnabledClass and is quite non-DI-like.
During testing (class, unit, or even end-to-end integration tests), it can valuable to stub behaviors at your program code boundaries – for instance, stubbing out the behavior of the NonDIEnabledClass above. Mocking frameworks can use fancy JVM bytecode re-writing techniques to intercept calls to new and swap in stubs at test time, but we can easily avoid JVM bytecode re-writing by managing third party library classes with Spring.
First, instruct Spring to create and manage an instance of this non-DI-enabled class. Declare a new configuration class in which you’ll add a method annotated with org.springframework.context.annotation.Bean (here the configuration class is named Bootstrap, though the name is irrelevant):
// configuration class
// used for advanced configuration
// such as to create DI-enabled instances of classes which do not have DI (JSR 330) annotations
class Bootstrap {
// use @Bean to annotate a method which returns an instance of the class that you want to inject and of which
// Spring should manage the lifecycle
@Bean(initMethod = "init", destroyMethod = "close")
def externalNonDIEnabledObject() = new NonDIEnabledClass()
}
Note how the optional initialization and teardown methods can be specified as parameter values to the Bean annotation as “initMethod” and “destroyMethod“.
Now, wire the instance of this class in where it is desired, for instance, in our Http class from above:
@Named
// see the Bootstrap class for how non-DI annotated (JSR 330) objects make their way into the object graph
class Http @Inject() (val externalNonDIEnabledObject: NonDIEnabledClass) {
def get(url: String): String = {}
}
Note the differences between the former and latter examples of the Http class. In the latter example:
Http class does not use new to instantiate the NonDIEnabledClass.@PostConstruct nor @PreDestroy methods are necessary in the Http class to manage the lifecycle of the NonDIEnabledClass instance.Your code is now wired up and ready for execution. Spring DI now needs to be activated.
Having now seen concrete examples of how to DI-enable your classes, let’s return to a Spring app’s lifecycle:
@Named@Inject points on your classes@PostConstruct methods on these instances@PreDestroy methods on these instancesTo activate Spring, create an instance of an org.springframework.context.annotation.AnnotationConfigApplicationContext, scan the package containing your DI-enabled classes, refresh the context, start the context, then register a shutdown hook. In this example, this code is located in an object called Bootstrap, which extends App for direct execution when Scala starts up (see more on this in a moment).
// main entry point for command line operation
object Bootstrap extends App {
// start up the Spring DI/IOC context with all beans in the info.raack.sailingcruisechecker namespace
val context = new AnnotationConfigApplicationContext()
// include all DI annotated classes in this project's namespace
context.scan("info.raack.sailingcruisechecker")
context.refresh()
// start up the app - run all JSR250 @PostConstruct annotated methods
context.start()
// ensure that all JSR250 @PreDestroy annotated methods are called when the process is sent SIGTERM
context.registerShutdownHook()
}
If you’ve included a class definition for the Bootstrap class to manage the lifecycle of third party class instances, you’ll also need to register these instances. Add a register(classOf[Bootstrap]) call to the definition above:
// start up the Spring DI/IOC context with all beans in the info.raack.sailingcruisechecker namespace
val context = new AnnotationConfigApplicationContext()
// include all custom class instances which are not DI enabled
context.register(classOf[Bootstrap])
// include all DI annotated classes in this project's namespace
context.scan("info.raack.sailingcruisechecker")
We’re ready to start our app! I’ll assume use of the sbt build system for this Scala program.
First, include the Spring libraries that you’ll need for DI in the build.sbt file. This includes spring-beans and spring-context. I also like to use slf4j as a logging facade and logback as a logging backend, and since Spring still uses commons-logging as a backend, I redirect commons-logging into slf4j with jcl-over-slf4j and then include logback as the final backend.
// libraries
libraryDependencies ++= Seq(
"org.springframework" % "spring-context" % "4.1.6.RELEASE" exclude ("commons-logging", "commons-logging"),
// spring uses commons-logging, so redirect these logs to slf4j
"org.slf4j" % "jcl-over-slf4j" % "1.7.12",
"org.springframework" % "spring-beans" % "4.1.6.RELEASE",
"javax.inject" % "javax.inject" % "[1]",
// logging: log4s -> slf4j -> logback
"org.log4s" %% "log4s" % "1.1.5",
"ch.qos.logback" % "logback-classic" % "1.1.3"
)
Next, I’ll indicate the main class for starting up the program. You may want to do this if you choose to bundle all of your code and third party libraries together with the assembly plugin or something similar.
// main class
mainClass in (Compile, packageBin) := Some("info.raack.sailingcruisechecker.Bootstrap")
Finally, start up the app:
sbt run
If all is well, Spring should be started and your app will run!
Several months back, I was presented with an opportunity to join a new R&D team at my employer. The individuals in the team all had different skill sets and hailed from different backgrounds. What brought them together was a challenge to extract the essence of business offerings from unstructured human-written (often poorly written) reviews using modern NLP techniques, refreshed and updated daily to the tune of hundreds of millions of reviews. This project had been in research mode for some months before my joining the team, but after some internal organizational restructuring, it had piqued the interest of key business and technology leaders and was bestowed a formal team and dedicated (though slim) engineering resources. My own interest in this team came from the opportunity to design and build a scalable NLP computation engine for the task at hand, with a very small set of engineers at my disposal – only one of which had worked on true production systems in the past. Perhaps a daunting task, but I was excited to tackle it – and to learn as many new and unique technologies as I could while doing so.
Upon discussing the current state of the research and implementation with team members, I was surprised to find that the team had chosen Scala as the language choice with Apache Spark as the runtime engine for text processing. Not surprised because I thought this was a bad decision, but rather that my organization was (and still is) currently in some ambiguous stage between “wild-west coyboy driven startup” and “heel-dragging corporate behemoth” which tends to eschew trendy technology choices that don’t have a sizable production legacy (as Java does). Having spent many years with the JVM on Java alone, I became interested in Scala years back – just not enough to do much more than dip my toes in whatever it is one dips ones toes in when investigating a new programming language. Ready to take my JVM-based programming ego down a few notches, I dove into the team head first and was pleasantly surprised by what I found.
Where should we put Scala?
Almost immediately upon quizzing my new teammates for details about their current software, I was bombarded by some highly charged discussions regarding previous technology choices. Comments like “yeah, we’re using Scala because Alice and Bob think that it’s cool”, “nobody supports this here; now that you’re helping us, Taylor, can you re-evaluate Scala’s use?”, and “I hate Scala” were frequent refrains. They were almost as popular as “we really want to run on Spark, and Scala supports many of the computation primitives that I’d rather not write in Python” and “Christine and Dave just need to practice more and they’ll see why Java is for dinosaurs” (names have been changed to protect the innocent). In fact, I myself was at first slightly miffed at being called a “dinosaur” – but I bottled up my own verbal defenses and tried not to be offended. Everyone’s opinion came from a different viewpoint; I wanted to figure out why the reactions had been so polar.

Perhaps the most eager of the Scala-defenders led me to a Paul Graham blog entry from 2001 entitled “Beating the Averages”. (I had actually been led donkey-style to this article in the past, but admittedly didn’t parse past the first few sentences.) In a nutshell, Paul Graham’s argument is that using efficient, non-mainstream technologies (programming languages in particular) that competitors ignore provides a competitive edge. He goes on to talk about “The Blub Paradox” regarding the “power” of computer languages, and asserts that “the only programmers in a position to see all the differences in power between the various languages are those who understand the most powerful one”. He wrote that by choosing a language which he considered at the time to be very powerful, his “resulting software did things our competitors’ software couldn’t do”. (For those interested, a cursory search for “Blub Paradox” provided this page as a counterexample to its merits.) This was the argument presented to me by my co-worker – that by choosing a language more powerful than Java, our team would be able to approach and solve our business problems in a better way that would be harder for others to replicate. While I didn’t take Graham’s comments about his language of choice specifically to heart (Graham speaks very candidly about his love for Lisp), the article and my co-worker’s argument did strike me and I set off to dive into the world of Scala.
One more note from the Scala-defender from above – one of the more compelling statements they made to me was that “Scala raises the level of abstraction from Java by managing language complexity that Java cannot get rid of”. As I travelled along my Scala learning path, I quickly found this to be the case.
The first stop along my foray into Scala came in the form of Scala for the Impatient by Horstmann. Admittedly, I found that I was a bit impatient – I didn’t make it past the first two chapters. Upon reaching chapter three, entitled “Working with Arrays”, I skipped directly to reading my co-workers source code. My own brain learns by looking and manipulating concrete examples, and for me the best way to do this has always been to start with the most familiar pieces of a new domain, such as an existing business process encoded into a computer program.

Having a background in Ruby, Python (with some ancient Scheme / Lisp knowledge) as well as Java, much of what I read seemed to make sense, with a few exceptions. Going to the web and humans for help, I quickly realized what many before me have said – there are many, perhaps too many, mechanisms for achieving very simple logical operations such as method calls, transforms, variable name references, etc. So many that it can be a bit confusing for the relative newcomer, as there are a variety of “canonical” style guides which seem to be produced by different camps in the Scala community. As it was described to me by one co-worker (who is regularly in conversations with Scala and Spark advocates in the San Francisco Bay Area), there are two main groups supporting Scala today: a group which is very interested in using the language as a research tool for language design itself, and a group which is very interested in language feature stability, ease of use and comprehensibility, and wide adoption for community support. Being an engineer who has spent many years in the halls of production hot-fixes, support, junior engineer mentorship, and consensus-building through standards and convention, I quickly realized that I aligned much more closely with the latter camp.
Fast-forward two months. I think I’ve gotten a good grip on how to approach programming from a Scala-standpoint, mostly through writing patches and new features for the previously mentioned big-data processing program running on Spark. In addition to understanding how one uses Scala pragmatically for actually getting real work done, diving into the runtime details has also opened my eyes to how one writes effective programs for Spark (more on that to come later, perhaps). I have a pretty good handle on the build process, how many concepts in Maven builds work with SBT, and what to do when things go wrong. With my newfound knowledge, I coded up a very basic app to prove my skills to myself – see it on Github if you’re interested. I’ll likely go into a little more detail about that project in the future as a very small case study.
Some resources that I found along the way that others might find helpful:
With luck, I’ll continue to learn and grow more proficient with Scala. I think I’m at the point that I’d consider writing my own programs in Scala when starting from the ground up – we’ll see how that goes in the next few months.