Humans learn through observing behavior from others. They watch and emulate the behaviors they see, making adjustments to their own actions along the way, given feedback. The same technique can be used in autonomous vehicles to model driving behavior based on direct observation of human driving. This technique is known as behavioral cloning.
I created a software suite to implement behavioral cloning for generating autonomous vehicle steering control. Using a front-facing video stream of safe driving paired with steering angles as training data, I built a convolutional neural network and trained it (using Keras) to clone driving behavior. Given a set of three front-facing camera images (front, left, and right), the model outputs a target steering wheel command.
The following techniques are used in this system:
- Use a vehicle simulator to generate and collect data of good driving behavior
- Build and train a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road
Exploring my implementation
All of the code and resources used in this project are available in my Github repository. Enjoy!
Technologies used
- Python
- Keras
- NumPy
- OpenCV
- Scikit-learn
Training a model
python model.py
Will train a model to drive the vehicle in the simulator.
Driving the simulated vehicle using the model
Once the model has been saved, it can be used with drive.py using this command:
python drive.py model.h5
Note: There is a known local system setting issue with replacing “,” with “.” when using drive.py. When this happens it can make predicted steering values clipped to max/min values. If this occurs, a known fix for this is to set the environment variable LANG to en_US.utf8.
Saving a video of the simulated vehicle using the model
python drive.py model.h5 run1
python video.py run1
Will create a video of the simulated vehicle driving with the model. The output will be a file called run1.mp4.
Optionally, one can specify the FPS (frames per second) of the video:
python video.py run1 --fps 48
Will run the video at 48 FPS. The default FPS is 60.
Model Architecture
The overall strategy for building the software’s neural network was to start with a well-known and high-performance network, and tune it for this particular steering angle prediction task.
This system includes a convolutional neural network model similar to the published NVidia architecture used for their self-driving car efforts, given that this system is attempting to solve the exact same problem (steering angle command prediction) and NVidia’s network is state of the art. This network inputs 160×320 RGB images from multiple camera angles at the front of a vehicle and outputs a single steering wheel angle command. One convolutional and one fully connected layer were removed from the NVidia architecture to reduce memory processing costs during training.
Before the convolutional layers of the model, a cropping layer removes the top (including sky) and bottom (including car image), to reduce noise in training. An additional layer normalizes the data points to have zero mean and a low standard deviation.
In between the convolutional layers, RELU activations are included to introduce non-linearity, max pooling to reduce overfitting and computatational complexity, and 50% dropout during training (also to reduce overfitting).
In between the fully-connected layers of the model, RELU activations are also introduced.
The input images are cropped to remove the top 50 and bottom 20 pixels to reduce noise in the image which are likely to be uncorrelated with steering commands. Each pixel color value in the image is then normalized to [-0.5,0.5].
Neural Network Layers
The network includes:
- input cropping and normalization layers
- four convolutional layers
- three 5×5 filters with 24, 36, and 48 depth
- one 3×3 filter with 64 depth
- a maximum pooling layer with 2×2 pooling
- three fully-connected layers with 100, 50, and 10 outputs
- a final steering angle output layer
| Layer | Description |
|---|---|
| Input | 160x320x3 RGB color image |
| Cropping | 50 pixel top, 20 pixel bottom crop |
| Normalization | [0,255] -> [-0.5,0.5] |
| Convolution 5×5 | 1×1 stride, valid padding, output depth 24 |
| RELU | |
| Max pooling | 2×2 stride |
| Convolution 5×5 | 1×1 stride, valid padding, output depth 36 |
| RELU | |
| Max pooling | 2×2 stride |
| Convolution 5×5 | 1×1 stride, valid padding, output depth 48 |
| RELU | |
| Max pooling | 2×2 stride |
| Convolution 3×3 | 1×1 stride, valid padding, output depth 64 |
| RELU | |
| Max pooling | 2×2 stride |
| Flattening | 2d image -> 1d pixel values |
| Fully connected | 100 output neurons |
| RELU | |
| Dropout | 50% keep fraction |
| Fully connected | 50 output neurons |
| RELU | |
| Dropout | 50% keep fraction |
| Fully connected | 10 output neurons |
| Output | Output – 1 steering angle command |
Model training
Dataset
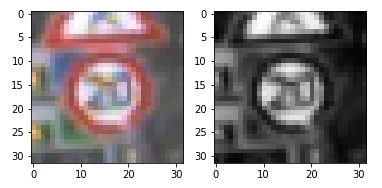
A vehicle simulator was used to collect a dataset of images to feed into the network. Training data was chosen to keep the vehicle driving on the road, which provided center, left, and right images taken from different points on the front of the vehicle. This data includes multiple laps using center lane driving. Here is an example image of center lane driving:

I then recorded the vehicle recovering from the left side and right sides of the road back to center so that the vehicle would learn to correct major driving errors when the vehicle is about to run off the road. These images show what a recovery looks like starting from the left side:



To augment the data set, I also flipped images and angles during training to further generalize the model. After the collection process, I had 8253 data image frames, each including center, left, and right images for a total of 24759.
Training
During training, the entire image data set is shuffled, with 80% of the images being used for training and 20% used for validation. I configured the Keras training to use an early stopping condition based on knee-finding using the validation loss, with a patience of 2 epochs. Also, an Adam optimizer is used so that manually training the learning rate is not necessary.
Video Result
The simulated vehicle drives around the entire track without any unsafe driving behavior; in only one spot did the simulated vehicle get close to running of the track on a curve (but did not leave the driving surface, pop up on legdes, or roll over any unsafe surfaces).