A huge portion of the challenge in building a self-driving car is environment perception. Autonomous vehicles may use many different types of inputs to help them perceive their environment and make decisions about how to navigate. The field of computer vision includes techniques to allow a self-driving car to perceive its environment simply by looking at inputs from cameras. Cameras have a much higher spatial resolution than radar and lidar, and while raw camera images themselves are two-dimensional, their higher resolution often allows for inference of the depth of objects in a scene. Plus, cameras are much less expensive than radar and lidar sensors, giving them a huge advantage in current self-driving car perception systems. In the future, it is even possible that self-driving cars will be outfitted simply with a suite of cameras and intelligent software to interpret the images, much like a human does with its two eyes and a brain.
Semantic segmentation helps when asking the question “where is an object in a given image?”, which is a technique which is incredibly important in the field of scene understanding. Standard convolutional neural networks (which start with convolutional layers, followed by fully connected layers, followed by a softmax or other activation function) are great for classifying objects in an image. However, if we need to identify where in an image an object exists, we need a slightly different architecture. For example, if we want to highlight the road in a video stream, this kind of task applies.

This repository contains a software pipeline which identifies the sections of an image which represent the road in images from a front-facing vehicle camera. The following techniques are used:
- Start with a pre-trained VGG model, used for image classification
- Remove the final fully connected layers
- Add 1×1 convolutions, upsampling, and skip layers
- Optimize the network with inference optimization techniques
- Retrain the network on labeled images from the KITTI Road Detection dataset
Exploring my implementation
All of the code and resources used in this project are available in my Github repository. Enjoy!
Technologies used
- Python
- Tensorflow
Scene understanding
Scene understanding is important to an autonomous vehicle’s ability to perceive its environment.
One method in scene understanding is to train multiple decoders on the same encoder; for example, one decoder for semantic segmentation, one for depth perception, etc. In this way, the same network can be used for multiple purposes. This project focuses solely on semantic segmentation.
Techniques for semantic segmentation
Fully Convolutional Networks
Fully convolutional networks, or FCNs, are powerful tools in semantic segmantation tasks. (Several other techniques have since improved upon FCNs: SegNet, Dialated Convolutions, DeepLab, RefineNet, PSPNet, Large Kernel Matters to name a few.) FCNs incorporate three main features beyond that of standard convolutional networks:
- Fully-connected layers are replaced by 1×1 convolutional layers, to preserve spatial information that would otherwise be lost
- Upsampling through the use of transpose convolutional layers
- Skip connections, which allow the network to use information from multiple resolutions to more precisely identify desired pixels
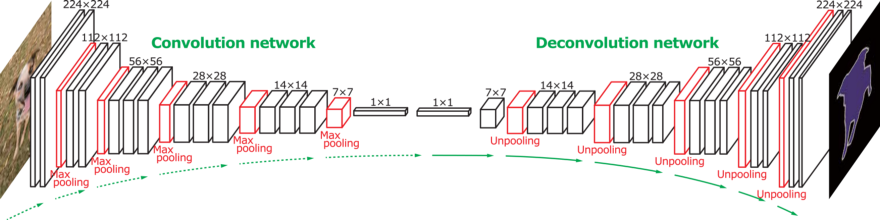
Structurally, a fully convolutional network is comprised of an encoder and a decoder.
The encoder is a series of standard convolutional layers, the goal of which is to extract features from an image, as in a traditional convolutional neural network. Often, encoders for fully convolutional networks are taken from VGG or ResNet, being pre-trained on ImageNet (another example of the power of transfer learning, another project I worked on.)
The decoder upscales the output of the encoder to be the same resolution as the original input, resulting in prediction or “segmentation” of each pixel in the original image. This happens through the use of transpose convolutional layers. However, even though the decoder returns the output in the original dimensions, some information about the “big picture” of the image (no pun intended) is lost due to the feature extraction in the encoder. To retain this information, skip connections are used, which add values from the pooling layers in the encoder to the output of the corresponding sized decoder transpose convolutional layers.
Performance enhancements
Because semantic segmentation performance on state of the art autonomous vehicle hardware may not be able to process a video stream in real-time, various techniques can be used to speed up inference by using less processing and memory bandwidth.
- Freezing graphs – by converting variables in a Tensorflow graph into constants once trained, memory costs decrease and model deployment can be simplified
- Fusion – by combining adjacent network nodes without forks, operations which would previous have used multiple tensors and processor executions can be reduced into one
- Quantization – by reducing precision of floating point constants to integers, memory and processing time can be saved
- Machine code optimization – by compiling the various system startup and load routines into a binary, overhead in inference is greatly reduced
Network architecture for semantic segmentation
A modified version of the impressive VGG16 neural network image classification pipeline is used as a starting point. The pipeline takes a pre-trained fully-convolutional network based on Berkeley’s FCN-8 network and adds skip layers.
From the originally inputted layer, the input, keep probability, and layers 3, 4, and 7 are extracted for further use.
Next, 1×1 convolutions are constructed from layers 3, 4, and 7 in an encoding step. Skip layers are inserted by adding the 1×1 convolutions from layers 3 and 4. Layers 3, 4, and 7 are deconvolved in reverse order to complete the final piece of the decoding step.
An Adam optimizer is used to minimize the softmax cross-entropy between the logits created by the network and the correct labels for image pixels.
The neural network is trained using a sample of labeled images for a maximum of fifty epochs. A mini-batch size of ten images is used compromise between high memory footprint and smooth network convergence. The training step has an early terminator which does not continue to train the network if total training loss does not decrease for three subsequent epochs.
Finally, a separate held-out sample of test images are run through the final neural network classifier for evaluation.
Results
Overall, the semantic segmentation network designed works well. The road pixels are highlighted in the test images with close to a human level of accuracy, with an occassional windshield or sidewalk highlighted as a road, and some road areas with shadows are missed.
Some example images segmented by the pipeline:



Future improvements
- Use the Cityscapes dataset for more images to train a network that can classify more than simply road / non-road pixels
- Augment input images by flipping on the horizontal axis to improve network generalization
- Implement another segmentation implementation such as SegNet, Dialated Convolutions, DeepLab, RefineNet, PSPNet, or Large Kernel Matters (see this page for a review)
- Apply trained classifier to a video stream
